
SQL语法和优化

SQL语法和优化
Miyako基础语法
DDL(Data Definition Language)
DDL: 数据定义语言,用来定义数据库对象(数据库、表、字段)
1 | -- 数据库操作 |
1 | -- 表操作 |
DML(Data Manipulation Language)
DML: 数据操作语言,用来对数据库表中的数据进行增删改操作
1 | -- 指定字段插入数据 |
DQL(Data Query Language)
DQL: 数据查询语言,用来查询数据库中表的记录
1 | -- 查询所有数据 |
1 | -- 聚合函数 |
DCL(Data Control Language)
DCL: 数据控制语言,用来创建数据库用户、控制数据库的控制权限
1 | -- 查询所有用户 |
外键约束
1 | -- 创建表时添加外键 |
多表查询
1 | -- 显式内连接 |
事务
四大特性ACID:
原子性(Atomicity):事务是不可分割的最小操作但愿,要么全部成功,要么全部失败
一致性(Consistency):事务完成时,必须使所有数据都保持一致状态
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17-- 开启事务
start transaction;
-- 提交事务
commit;
-- 回滚事务
rollback;
-- 设置隔离级别
set session transaction isolation level 隔离级别;
-- 隔离级别
read uncommitted;
read committed;
repeatable read;
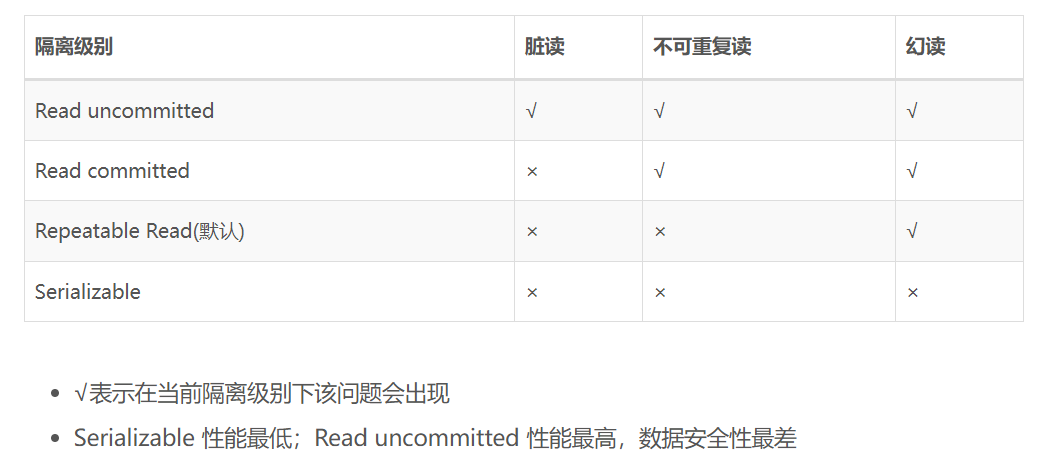
serializable;并发问题:
脏读: 一个事务读取到了另一个事务未提交的数据
不可重复读: 一个事务读取到了另一个事务已提交的数据
幻读: 一个事务读取到了另一个事务已提交的数据
SQL优化
存储引擎
1 | -- 查看存储引擎 |
InnoDB: 支持事务,支持行级锁,支持外键。
- xxx.ibd: xxx代表表名,InnoDB 引擎的每张表都会对应这样一个表空间文件,存储该表的表结构(frm、sdi)、数据和索引。
MyISAM: 不支持事务,支持表级锁,不支持外键。
- xxx.sdi: 存储表结构信息
- xxx.MYD: 存储数据
- xxx.MYI: 存储索引
Memory: 支持哈希索引,数据存储在内存中,数据易丢失。
- xxx.sdi: 存储表结构信息
存储引擎选择
在选择存储引擎时,应该根据应用系统的特点选择合适的存储引擎。对于复杂的应用系统,还可以根据实际情况选择多种存储引擎进行组合。
- InnoDB: 如果应用对事物的完整性有比较高的要求,在并发条件下要求数据的一致性,数据操作除了插入和查询之外,还包含很多的更新、删除操作,则 InnoDB 是比较合适的选择
- MyISAM: 如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性、并发性要求不高,那这个存储引擎是非常合适的。
- Memory: 将所有数据保存在内存中,访问速度快,通常用于临时表及缓存。Memory 的缺陷是对表的大小有限制,太大的表无法缓存在内存中,而且无法保障数据的安全性
电商中的足迹和评论适合使用 MyISAM 引擎,缓存适合使用 Memory 引擎。
索引
explain 各字段含义
- id:select 查询的序列号,表示查询中执行 select 子句或者操作表的顺序(id相同,执行顺序从上到下;id不同,值越大越先执行)
- select_type:表示 SELECT 的类型,常见取值有 SIMPLE(简单表,即不适用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等
- type:表示连接类型,性能由好到差的连接类型为 NULL、system、const、eq_ref、ref、range、index、all
- possible_key:可能应用在这张表上的索引,一个或多个
- Key:实际使用的索引,如果为 NULL,则没有使用索引
- Key_len:表示索引中使用的字节数,该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
rows:MySQL认为必须要执行的行数,在InnoDB引擎的表中,是一个估计值,可能并不总是准确的 - filtered:表示返回结果的行数占需读取行数的百分比,filtered的值越大越好
最左前缀法则: 最左前缀法则指的是在创建索引时,索引的字段顺序应该从最左边的字段开始,依次向右排列。
索引的创建和删除
1 | -- 创建普通索引 |
1 | -- 查看服务器的状态 |
索引结构
InnoDB 引擎选择使用 B+树 作为索引结构,是因为它适合磁盘存储环境下的大规模数据检索,并且能够很好地支持数据库的查询和范围操作。
优点:
- 提高数据检索效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗
缺点:
- 索引列也是要占用空间的
- 索引大大提高了查询效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
为什么选择B+树作为索引:
二叉树:
- 普通二叉树在插入或删除数据时可能会变得极度不平衡(如退化成链表),导致时间复杂度退化为 O(n)。
- 二叉树节点通常只存储一个数据项(键值),导致每次磁盘读取的利用率较低,增加了 I/O 次数。
- 二叉树的结构导致范围查询需要遍历多个节点,效率不高。
红黑树:
- 红黑树是一种自平衡二叉树,在插入或删除数据时,会通过旋转和重新着色等操作来保持树的平衡,从而保证树的高度不超过 log(n)。
- 红黑树通过颜色调整保持自身平衡,但调整的开销(旋转操作)较高。
- 红黑树每个节点只能存储一个键值,树的高度较高,在磁盘存储中增加了随机 I/O 操作次数。
- 红黑树的中序遍历能实现范围查询,但效率低,尤其在大数据量下,性能表现不佳。
B树:
- B树是一种平衡树,每个节点可以存储多个键值,树的高度较低,在磁盘存储中减少了随机 I/O 操作次数。
- B树的叶子节点不通过指针相连,范围查询时需要在多个叶子节点中反复查找,效率较低。
- 由于没有顺序链表,顺序读取需要频繁跳转到不同的节点,磁盘访问的性能较差。
- B树的非叶子节点也存储数据,会占用更多的存储空间,导致节点能存储的键值数量减少,树的高度增大。
为什么 InnoDB 存储引擎选择使用 B+Tree 索引结构?
- 相对于二叉树,层级更少,搜索效率高
- 对于 B-Tree,无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针也跟着减少,要同样保存大量数据,只能增加树的高度,导致性能降低
- 相对于 Hash 索引,B+Tree 支持范围匹配及排序操作
索引的存储形式
聚集索引:索引结构的叶子节点保存了行数据,必须有,而且只有一个。
二级索引:将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键,可以存在多个。
1 | select * from user where id = 10; |
对于上面两句SQL,利用id进行搜寻走的是聚集索引,利用name进行搜索走的是二级索引,需要回表查询,因此效率更低。
索引失效情况
- 在索引列上进行运算操作,索引将失效。如:
explain select * from tb_user where substring(phone, 10, 2) = '15'; - 字符串类型字段使用时,不加引号,索引将失效。如:
explain select * from tb_user where phone = 17799990015;,此处phone的值没有加引号 - 模糊查询中,如果仅仅是尾部模糊匹配,索引不会是失效;如果是头部模糊匹配,索引失效。如:
explain select * from tb_user where profession like '%工程';,前后都有 % 也会失效。 - 用
or分割开的条件,如果or其中一个条件的列没有索引,那么涉及的索引都不会被用到。 - 如果 MySQL 评估使用索引比全表更慢,则不使用索引。
覆盖索引
覆盖索引是指在查询过程中,只需要从索引中就能够获取到所需的数据,而不需要再访问数据表中的数据。
例如:
一张表,有四个字段(id, username, password, status),由于数据量大,需要对以下SQL语句进行优化,该如何进行才是最优方案:select id, username, password from tb_user where username='aaa';
则可以给username和password字段建立联合索引,则不需要回表查询,直接覆盖索引即可。
索引设计原则
- 针对于数据量较大,且查询比较频繁的表建立索引
- 针对于常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
- 尽量选择区分度高的列作为索引,尽量建立唯一索引,区分度越高,使用索引的效率越高
- 如果是字符串类型的字段,字段长度较长,可以针对于字段的特点,建立前缀索引
- 尽量使用联合索引,减少单列索引,查询时,联合索引很多时候可以覆盖索引,节省存储空间,避免回表,提高查询效率
- 要控制索引的数量,索引并不是多多益善,索引越多,维护索引结构的代价就越大,会影响增删改的效率
- 如果索引列不能存储NULL值,请在创建表时使用NOT NULL约束它。当优化器知道每列是否包含NULL值时,它可以更好地确定哪个索引最有效地用于查询
数据插入
大批量插入:
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令插入。
1 | load data infile '文件路径' into table 表名 fields terminated by ',' lines terminated by '\n'; |
update优化
在更新数据时,需要注意以下几点:
update student set no = '123' where id = 1;,这句由于id有主键索引,所以只会锁这一行;
update student set no = '123' where name = 'test';,这句由于name没有索引,所以会把整张表都锁住进行数据更新,解决方法是给name字段添加索引
InnoDB引擎
事务原理
原子性(Atomicity)
- 作用:保证事务不会因为部分操作失败而导致数据库处于不一致状态。
实现机制: - 依赖日志(如Redo和Undo日志) 来记录事务操作,支持回滚。
数据库通过 事务管理器 来监控事务的执行状态。
一致性(Consistency)
- 作用:确保数据库在事务完成后符合业务规则,数据不会发生逻辑错误。
- 实现机制:
检查约束条件:如唯一性、外键、检查约束等。
通过事务回滚机制恢复到一致状态。
隔离性(Isolation)
- 作用:保证事务执行的独立性,避免由于并发操作导致数据错误。
- 实现机制:
使用 锁机制(如共享锁、排他锁)。
设置 隔离级别(如读未提交、读已提交、可重复读、序列化)来控制并发行为。
数据库中使用多版本并发控制(MVCC) 来提升性能并保证隔离性。
持久性(Durability)
- 作用:保证提交后的数据不会丢失,增强数据库的可靠性。
- 实现机制:
通过 日志文件 和 事务提交确认。
数据库在事务提交时会将修改写入 磁盘,即使用 WAL(Write-Ahead Logging)机制确保日志先写入磁盘,再执行数据修改。使用 数据快照 和定期备份防止数据丢失
MVCC(多版本并发控制)
RC(Read Committed,读已提交)
- 每次读取数据时,都会读取最新的提交版本,每一次执行快照读时生成ReadView。
- 避免了 脏读(Dirty Read),但可能会出现 不可重复读(Non-repeatable Read)。
- 适用场景:性能优先的场景,如报表查询。
RR(Repeatable Read,可重复读)
- 每次读取数据时,都会读取事务开始时的快照版本,直到事务结束才释放锁。
- 避免了 脏读 和 不可重复读,但可能会出现 幻读(Phantom Read)。
- 适用场景:需要保证数据的一致性,如银行转账。
封面





